Digital Humanities & German Periodicals
As an undergraduate research assistant, I spent three years as the primary developer for an NLP-driven web application built to assist a humanities professor (Dr. Peter McIsaac, University of Michigan) with his research on 19th-century German literature. The application allowed him to run statistical topic models (LDA, HDP, DTM, etc.) on a large corpus of text and displayed helpful visualizations of the results. The application was built using Python / Flask / Bootstrap and also supported toponym detection and full-text search. We used gensim for topic modeling.
Using the web application I built, my supervisor was able study cultural and historical trends in a large corpus of previously unstudied documents. The results of this work were published in humanities journals and conferences, including [0] and [1].
Motivation
Our analysis focused on a corpus of widely-circulated periodicals, published in Germany during the 19th-century around the time of the administrative unification of Germany in 1871. Through HathiTrust and partnerships with university libraries, we obtained digital scans of the following periodicals:
- Deutsche Rundschau (1874-1964)
- Westermann’s Illustrirte Monatshefte (1856-1987)
- Die Gartenlaube (1853-1944)
These periodicals, published weekly or monthly, were among Germany’s most widely-read print material in the latter half of the nineteenth century, and served as precursors to the modern magazine. Scholars have long recognized the cultural significance of these publications [4], but their enormous volume had so far precluded comprehensive study.


Using statistical methods, including topic models, we aimed to study the development of a German national identity following the 1848 revolutions, through the 1871 unification, and leading up to the world wars of the twentieth century. This approach is commonly referred to as digital humanities or distant reading (in contrast to close reading).
Preprocessing
Initially, we only had access to digital scans of books printed in a difficult-to-read blackletter font. In order to convert our scanned images to text, I used Google Tesseract to train a custom optical character recognition (OCR) model specialized to fonts from our corpus. Tesseract performed quite well, but our scans exhibited a number of characteristics that introduced errors into the OCR process:
- Poor scan quality (causing speckles, erosion, dilation, etc.)
- Orthographic differences from modern German, including ligatures and the long s
- Inconsistent layouts (floating images, multiple columns per page, etc.)
- Blackletter fonts which are difficult to read, even for humans
- The use of fonts such as Antiqua for dates and foreign words
- Headers, footers, page numbers, illustrations, and hyphenation
The examples below highlight some of the challenges we faced during the OCR phase.



As a result, significant pre- and post-processing of OCR results was necessary. We combined a number of approaches in order to reduce the error rate to an acceptable level:
- I used Processing to remove noise and other scanning artifacts from our images.
- I wrote code to automatically remove running headers, text decorations, and page numbers.
- Through manual inspection of a small number of documents, we compiled a list of common OCR mistakes. I developed scripts to automatically propagate these corrections across the entire corpus.
- I experimented with several custom OCR-correction schemes to correct as many mistakes as possible and highlight ambiguities. Our most successful approach used a Hidden Markov Model to correct sequences of word fragments. Words were segmented using Letter Successor Entropy.
With these improvements, we found that our digitized texts were good enough for the type of exploratory analysis we had in mind. By evaluating our OCR pipeline on a synthetic dataset of “fake” scans with known text and a configurable amount of noise (speckles, erosion, dilation, etc.), we found that our OCR correction efforts improved accuracy from around 80% to 95% or higher.
Topic Modeling
In natural language processing, topic modeling is a form of statistical analysis used to help index and explore large collections of text documents. The output of a topic model typically includes:
- A list of topics, each represened by a list of related words. Each word may also have an associated weight, indicating how strongly a word relates to this topic. For example:
- (Topic 1) sport, team, coach, ball, coach, team, race, bat, run, swim…
- (Topic 2) country, government, official, governor, tax, approve, law…
- (Topic 3) train, bus, passenger, traffic, bicycle, pedestrian…
- A topic probability vector for each document, representing the importance of each topic to this document. For example, a document about the Olympics may be 70% sports, 20% government, and 10% transportation.
The most popular topic model is Latent Dirichlet Allocation (LDA), which is succinctly described by the following probabilistic graphical model [5]. There are topics, documents, words per document, and words in the vocabulary.

Each topic is represented by a probability distribution over the vocabulary, indicating how likely each word is to appear under topic . LDA posits that documents are written using the following generative process:
- For each document ,
- Decide in what proportions each topic will appear.
- To choose each each word ,
- According to , randomly decide which topic to use for this word.
- Randomly sample a word according to the chosen topic.
Of course, this is not how humans actually write. LDA represents documents as bags-of-words, ignoring word order and sentence structure. When topic models are used to index or explore large corpora, as was our goal, this is an acceptable compromise. Given a collection of documents, LDA attempts to “invert” the generative process by computing a maximum likelihood estimate of the topics and topic mixtures . These estimates are typically computed using variational expectation-maximziation.
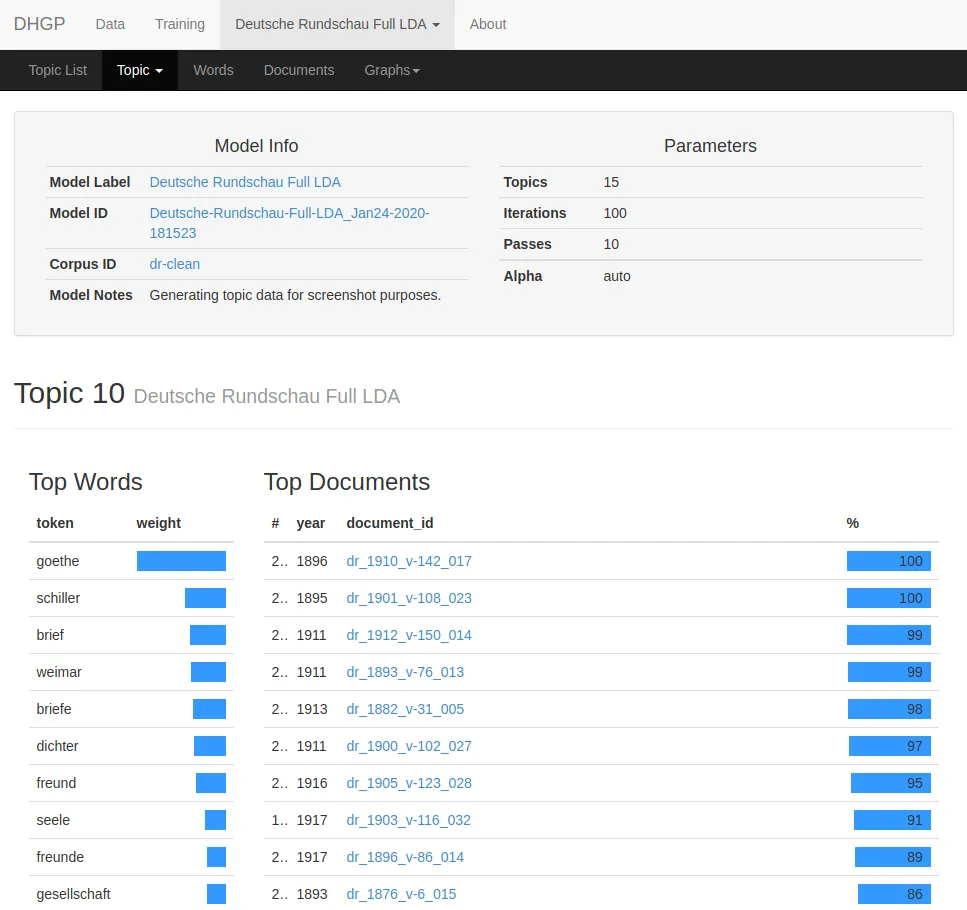
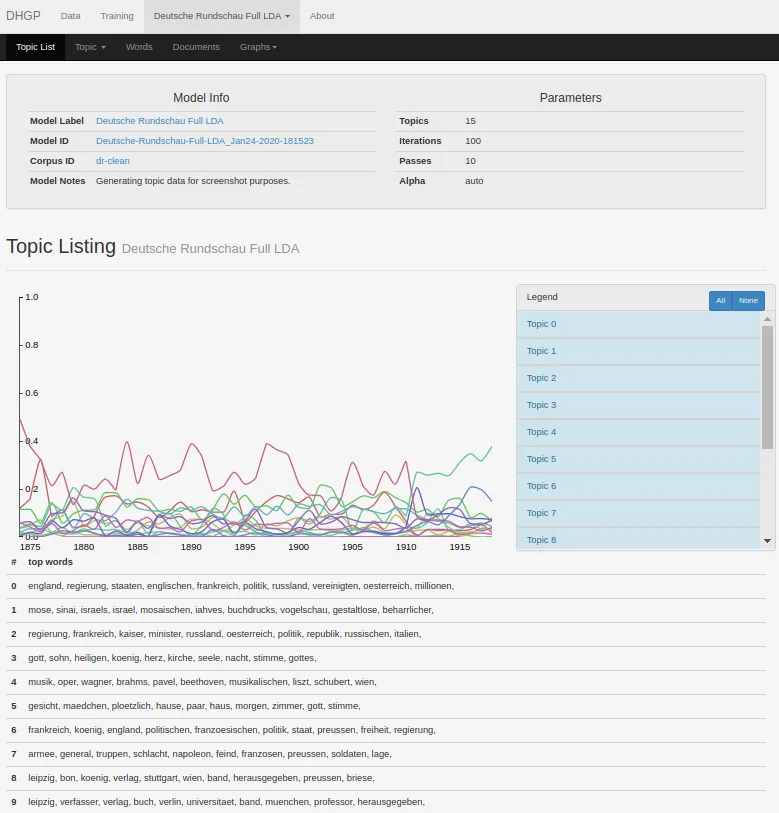
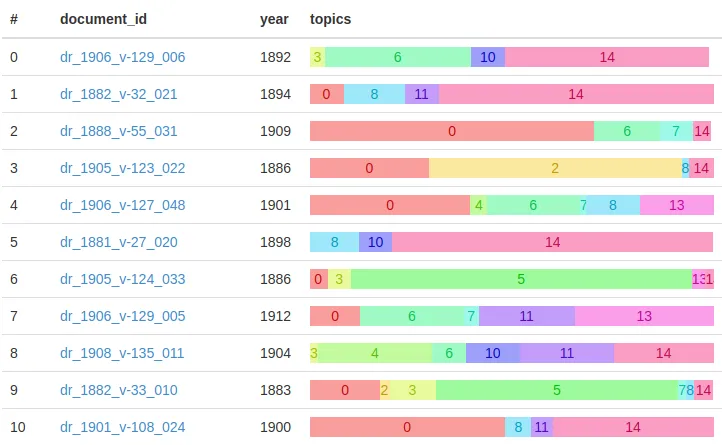
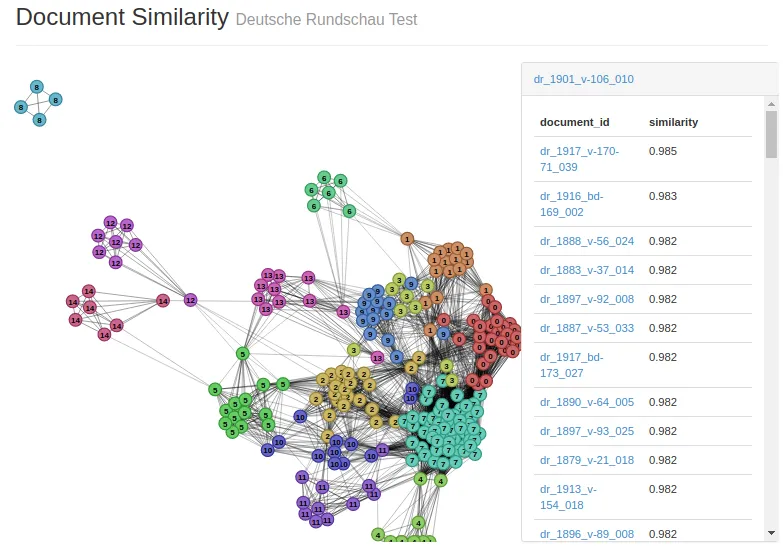
DHGP Browser
Using Python / Flask / Bootstrap, I built a web application enabling humanities researchers to train, visualize, and save topic models. Features:
- Support for several popular topic models:
- Online Latent Dirichlet Allocation ([6], via
gensim) - Online Hierarchical Dirichlet Process ([7], via
gensim) - Dynamic Topic Models (custom implementation based on [8])
- Online Latent Dirichlet Allocation ([6], via
- Toponym Resolution for identifying and mapping place names mentioned in our texts
- Full-text / metadata search using ElasticSearch
- Support for any corpus with metadata saved in JSON format.
I no longer have access to the most up-to-date version of dhgp-browser, but here are some screenshots from mid-2015:
UROP Symposium Poster
The poster below summarizes the progress made during my first year on the project, which I initially joined through the UROP Program at UM. After my first year, I was hired to continue working on the project as an undergraduate research assistant.
